Yapay zeka teknolojisinin son yıllardaki hızlı gelişimi, beraberinde önemli bir sorunu gündeme getiriyor: veri açlığı. Özellikle büyük dil modelleri (LLM’ler), her geçen gün daha fazla veriye ihtiyaç duyarken, mevcut veri kaynaklarının sınırlarına yaklaşılıyor. Epoch AI araştırmacılarının öngörülerine göre, 2028 yılına kadar yapay zeka modellerinin eğitim veri ihtiyacı, mevcut kamusal çevrimiçi metin stoğunun tamamına ulaşacak.
Veri Tüketiminin Boyutları
Artan Veri İhtiyacı
LLM’lerin eğitiminde kullanılan token (kelime parçaları) sayısı, 2020’den bu yana yüz kat artış gösterdi. Günümüzde bu sayı onlarca trilyona ulaşmış durumda. İnternet’teki toplam metin verisi stoğu yaklaşık 3.100 trilyon token olarak tahmin ediliyor.
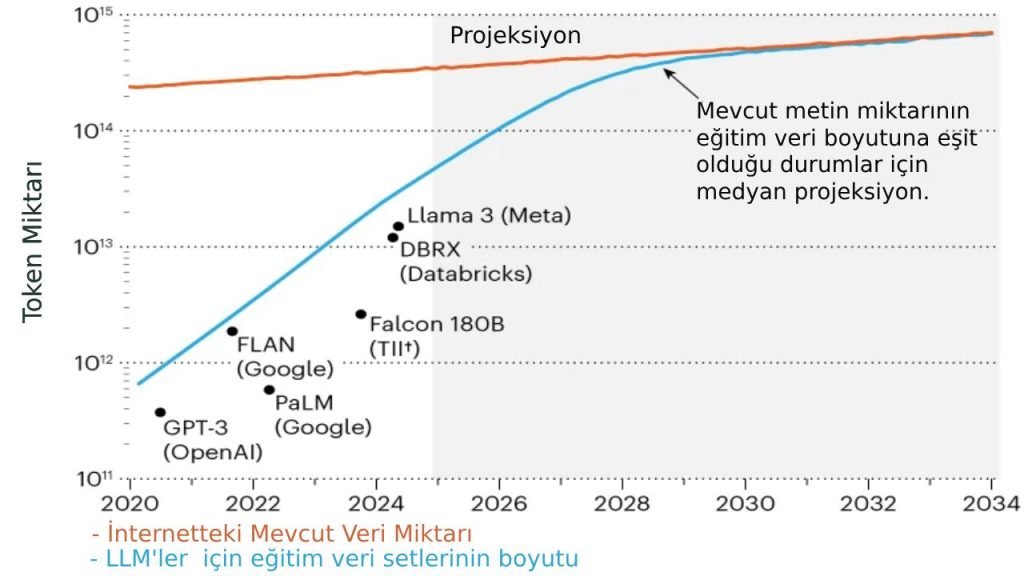
Veri Büyüme Hızı
İnternet içeriğinin yıllık artış hızı %10’un altında kalırken, yapay zeka eğitim veri setlerinin boyutu her yıl ikiye katlanıyor. Bu dengesiz büyüme, yakın gelecekte ciddi bir veri darboğazına işaret ediyor.
Veri Erişim Engelleri ve Yasal Zorluklar
İçerik Sağlayıcıların Tepkisi
Web sitesi sahipleri ve içerik üreticileri, verilerinin yapay zeka eğitiminde kullanılmasını engellemek için çeşitli önlemler alıyor. 2024’te yüksek kaliteli web içeriğinin %20-33’ü web tarayıcılarına kapalı durumda.
Hukuki Süreçler
The New York Times’ın OpenAI ve Microsoft’a açtığı telif hakkı davası, veri kullanımının yasal boyutunu tartışmaya açtı. Bu tür davalar, özellikle akademik araştırmacılar için veri erişimini zorlaştırabilir.
Alternatif Veri Kaynakları
Özel Veri Setleri
WhatsApp mesajları, YouTube transkriptleri gibi kamuya açık olmayan veriler potansiyel kaynaklar arasında. Ancak bu verilerin toplam hacmi yaklaşık bir katrilyon token ile sınırlı.
Uzmanlaşmış Veri Kümeleri
Stanford Üniversitesi araştırmacılarına göre, sağlık hizmetleri, çevre ve eğitim alanlarındaki henüz kullanılmayan veriler önemli bir potansiyel sunuyor.
Yenilikçi Çözüm Yaklaşımları
Sentetik Veri Üretimi
OpenAI’nin günde 100 milyar kelime üretme kapasitesi, sentetik verilerin potansiyelini gösteriyor. Ancak bu yaklaşım, “Model Otofaji Bozukluğu” gibi riskleri de beraberinde getiriyor.
Verimli Eğitim Teknikleri
Yeni araştırmalar, aynı veri setinin birkaç kez kullanılmasının öğrenme performansını artırabileceğini gösteriyor. Stanford Üniversitesi’nin çalışmaları, dört kez tekrar okumanın optimal olduğunu ortaya koyuyor.
Sonuç ve Gelecek Perspektifi
Veri krizi, yapay zeka endüstrisini daha verimli ve sürdürülebilir çözümler geliştirmeye zorluyor. Uzmanlaşmış modeller, sentetik veri üretimi ve gelişmiş eğitim teknikleri, bu sorunun aşılmasında önemli rol oynayacak.


Yapay zeka rahatlıkla yalan söylüyor. O yüzden korkuyorum.